Jeśli obrazy nie wyświetlają się poprawnie, można skorzystać z wersji Non-SVG.
SVG zostało dezaktywowane. (Aktywuj SVG ponownie)
Niniejsza strona zawiera skondensowane informacje o najpopularniejszych komendach wykorzystywanych w systemie kontroli wersji GIT, w formie wizualnej oraz tekstowej. Jeśli posiadasz podstawową wiedzę na temat działania GITa, strona ta pozwoli Ci na pełne zrozumienie i utrwalenie poznanych dotąd informacji. Szczegóły dotyczące tego, jak powstała niniejsza witryna, znajdziesz w moim repozytorium GitHub.
Polecam również: Visualizing Git Concepts with D3
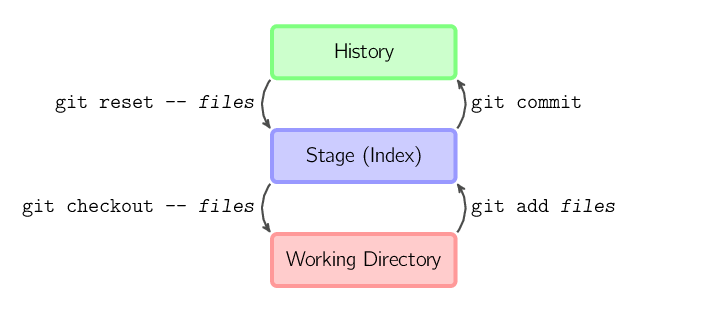
Cztery komendy przedstawione poniżej służą do kopiowania plików pomiędzy katalogiem roboczym (working directory), przechowalnią (Index lub Stage) oraz katalogiem Git (History) zawierającym commity.
git add files kopiuje pliki (w ich aktualnym stanie) do przechowalni (stage).git commit zapisuje migawkę (snapshot) przechowalni (stage) jako nowy commit.git reset -- files usuwa pliki z przechowalni (stage); oznacza to, że komenda ta kopiuje pliki z ostatniego commita do przechowalni (stage), nadpisując jej stan. Używa się jej między innymi do "cofania" komendy git add files. Komendy git reset można użyć również do całkowitego usunięcia wszystkich zmian.git checkout -- files kopiuje pliki z przechowalki (stage) do katalogu roboczego (working directory). Komendy tej używa się do cofnięcia wszelkich zmian lokalnych.Można również użyć git reset -p, git checkout -p, lub
git add -p zamiast (lub oprócz) wyszczególniania konkretnych elementów. Wówczas można wybrać je w sposób interaktywny.
Możliwe jest również bezpośrednie przeskoczenie do historii commitów i sprawdzenie plików bezpośrednio, bez konieczności wcześniejszego przeniesienia ich do przechowalni (stage).
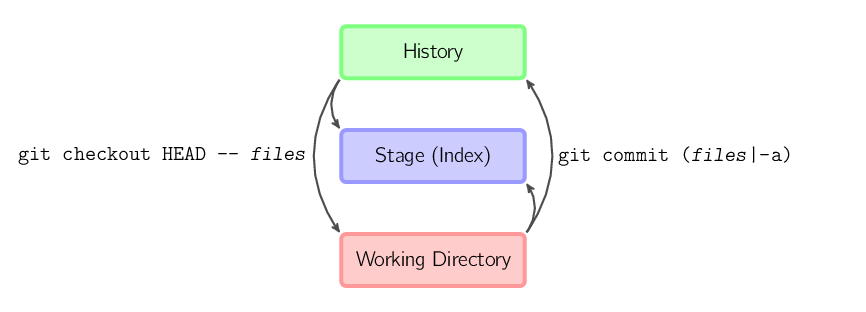
git commit -a automatycznie dodaje zmiany ze wszystkich znanych plików (dotyczy to zarówno git add jak i git rm dla plików usuniętych z katalogu roboczego (working directory)), a następnie wykonuje komendę git commit.git commit files tworzy nowy commit, który zawiera całą zawartość ostatniego commita oraz migawkę (snapshot) wybranych plików. Oczywiście pliki kopiowane są również do przechowalni (stage).git checkout HEAD -- files kopiuje pliki z ostatniego commita zarówno do przechowalni (stage) jak i katalogu roboczego (working directory).W dalszej części tego dokumentu będą używane grafiki w następującej formie.
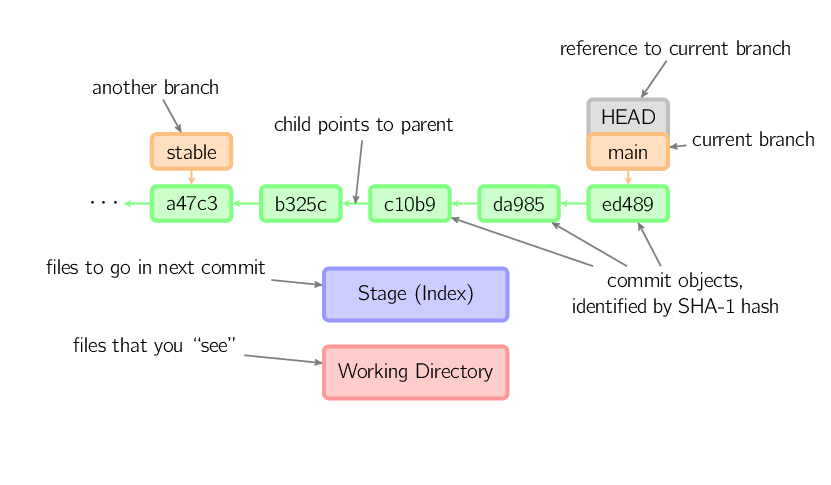
Commity pokazane są w zielonych polach jako pięcioznakowe identyfikatory, które wskazują na swoich rodziców (wcześniejsze commity). Gałęzie (branche) pokazane są w pomarańczowych polach i wskazują na aktualne commity. Aktualne gałęzie (branche) można zidentyfikować dzięki specjalnemu oznaczeniu HEAD, które w rzeczywistości jest "przyczepione" do gałęzi (brancha), w której się aktualnie znajdujemy. Na pokazanej grafice widzimy pięć ostatnich commitów, spośród których ed489 jest najbardziej aktualnym. main (aktualna gałąź - branch) wskazuje na ten commit, podczas gdy stable (inna gałąź - branch) wskazuje na przodka gałęzi (branch) main i jej commit.
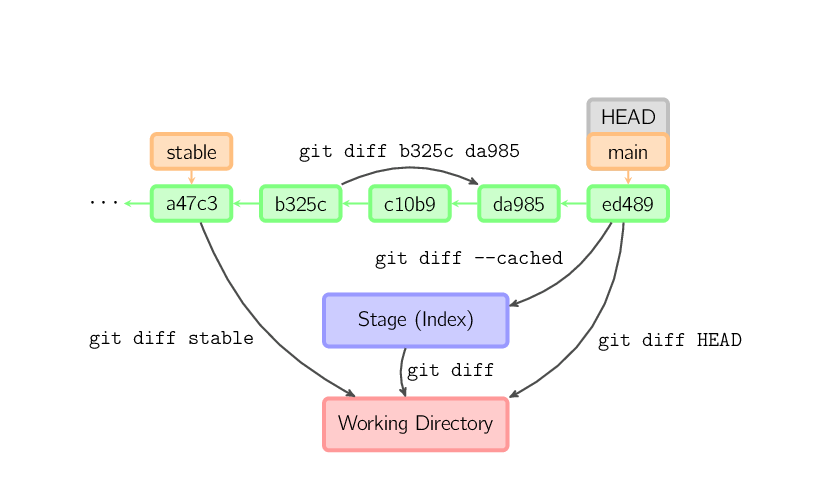
Istnieje wiele sposobów na przejrzenie różnic pomiędzy poszczególnymi commitami. Poniżej przedstawionych jest kilka przykładów często używanych kombinacji. Każda z tych komend może przyjmować dodatkowe argumenty, które potrafią limitować pokazywane różnice jedynie do wskazanych plików.
Kiedy zatwierdzasz (commitujesz) zmiany, Git tworzy nowy obiekt używając plików znajdujących się w przechowalni (stage), jednocześnie wskazując jako swojego rodzica ostatni istniejący commit. Następnie aktualna gałąź (branch) zaczyna wskazywać na właśnie tworzony commit. Na grafice umieszczonej poniżej aktualna gałąź (branch) to main. Zanim komenda została wykonana, gałąź (branch) main wskazywała na commit ed489. Po jej wykonaniu nowy commit oznaczony jako f0cec został utworzony z rodzicem w postaci ed489, a następnie gałąź (branch) main została przeniesiona na nowy commit.
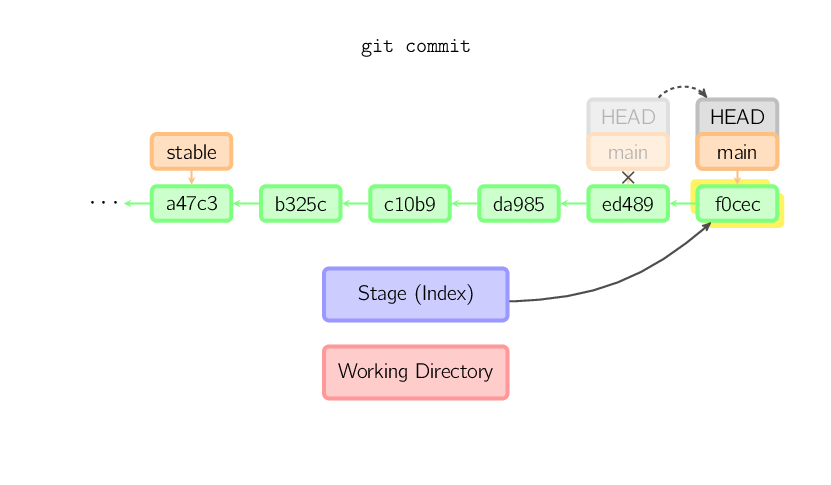
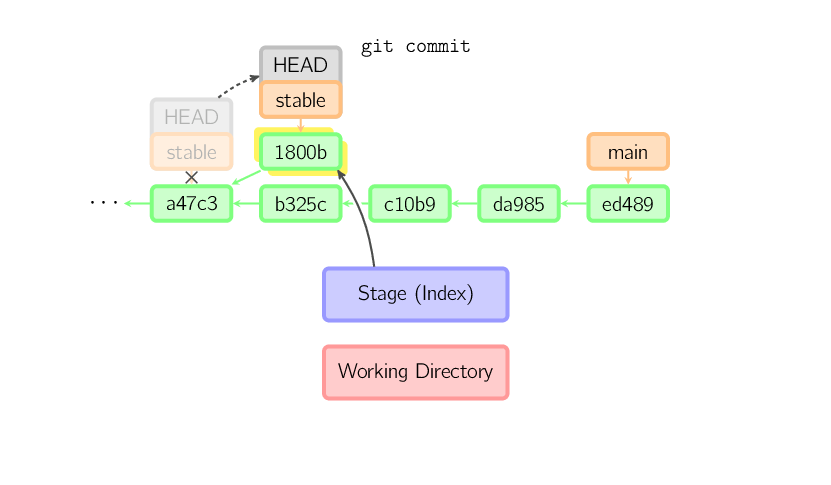
Ten sam proces następuje również w przypadku gałęzi (brancha) będącego przrodkiem innej gałęzi. Poniżej widzimy commit wykonany w gałęzi stable, która jest przodkiej gałęzi main. Nowy commit oznaczony jest jako 1800b. Po tej operacji gałąź (branch) stable nie jest już przodkiem gałęzi main. Aby połączyć obie gałęzie będzie konieczne wykonanie merge (lub rebase).
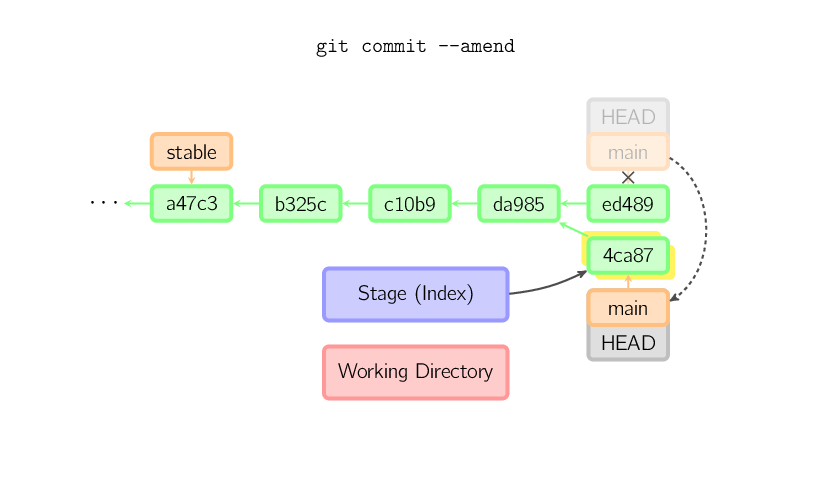
Czasem może zdarzyć się tak, że w commicie pojawi się błąd (na przykład zostanie zawarty inny komentarz niż był planowany). Wówczas można użyć komenty git commit --amend. Wówczas git utworzy nowy commit z tym samym rodzicem, co niedawno utworzony commit. Dzięki temu błędny commit zostanie zastąpiony nowym i nie będzie częścią całego łańcucha. Commit z błędem zostanie zwyczajnie usunięty, pod warunkiem, że żaden inny element nie jest z nim powiązany.
Ostatnim przypadkiem jest commit z detached HEAD, który zostanie wyjaśniony w dalszej części.
Komenda checkout używana jest do kopiowania plików z katalogu Git (history) lub z przechowalni (stage) do katalogu roboczego (working directory). Oprócz tego wykorzystuje się ją również do zmiany gałęzi (branch).
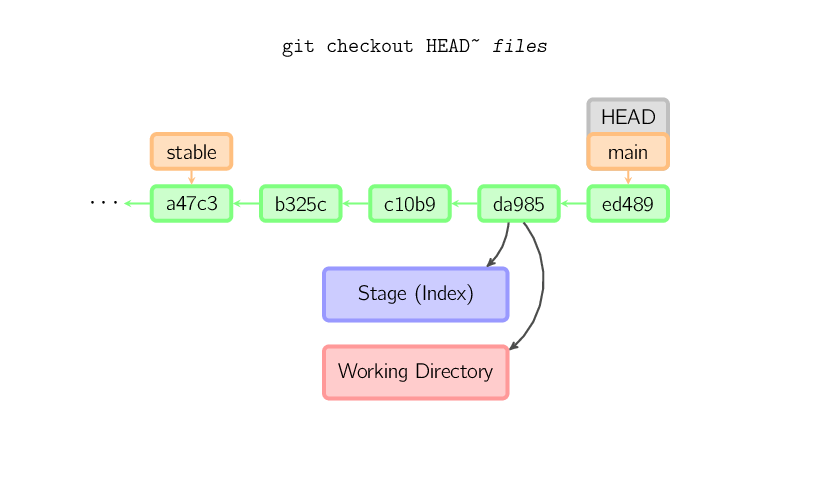
Kiedy podany zostanie argument w postaci nazwy pliku (lub przełącznika -p) git skopiuje podane pliki z podanego w komendzie commita do przechowalni (stage) oraz do katalogu roboczego (working directory). Przykładowo, komenda git checkout HEAD~ foo.c skopiuje plik foo.c z commitu oznaczonego jako HEAD~ (rodzic aktualnego commita) do katalogu roboczego (working directory) oraz do przechowalni (stage). Należy pamiętać, że operacja ta nie zmienia aktualnej gałęzi (branch). Jeśli nazwa commita nie zostanie podana, pliki zostaną skopiowane z przechowalni (stage) do katalogu roboczego (working directory).
Kiedy nie zostanie podana nazwa pliku tylko nazwa gałęzi (branch) w lokalnym repozytorium, HEAD zostanie przeniesione do podanej gałęzi (branch) - oznacza to "przełączenie się" do danej gałęzi (branch). Przechowalnia (stage) oraz katalog roboczy (working directory) zawierają wówczas elementy commita z aktualnej gałęzi (branch). Każdy z plików wchodzących w skład nowego commita (a47c3 poniżej) zostanie skopiowany; każdy plik wchodzący w skład starego commita (ed489) i jednocześnie nie istniejący w nowym, zostanie usunięty; każdy z plików wchodzących w skład innych commitów zostanie zignorowany.
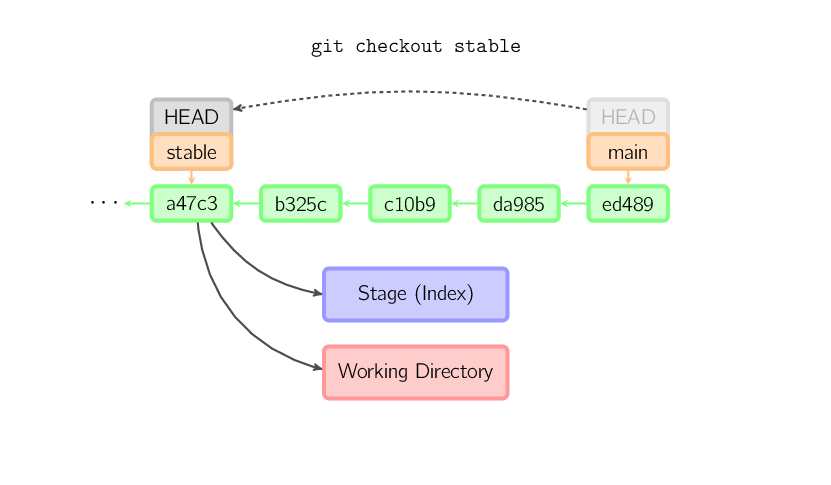
Kiedy ani nazwa pliku ani nazwa gałęzi (branch) z lokalnego repozytorium nie zostanie podana — zamiast tego może zostać podanty tag, gałąź zdalnego repozytorium, SHA-1 ID lub coś w rodzaju main~3 — otrzymamy anonimową gałąź (branch) zwaną detached HEAD. Jest ona przydatna do skakania po całej historii commitów. Powiedzmy, że chcemy skompilować wersję 1.6.6.1 gita. Możemy wykonać komendę git checkout v1.6.6.1 (jest to tag, nie nazwa gałęzi (branch)), skompilować, zainstalować gita, a następnie wrócić do głównej gałęzi main, wydając komendę git checkout main. Mimo tej prostoty i podobieństw do zwykłej wersji tej komendy, commitowanie z wykorzystaniem detached HEAD działa trochę inaczej niż zazwyczaj; zostało to opisane poniżej.
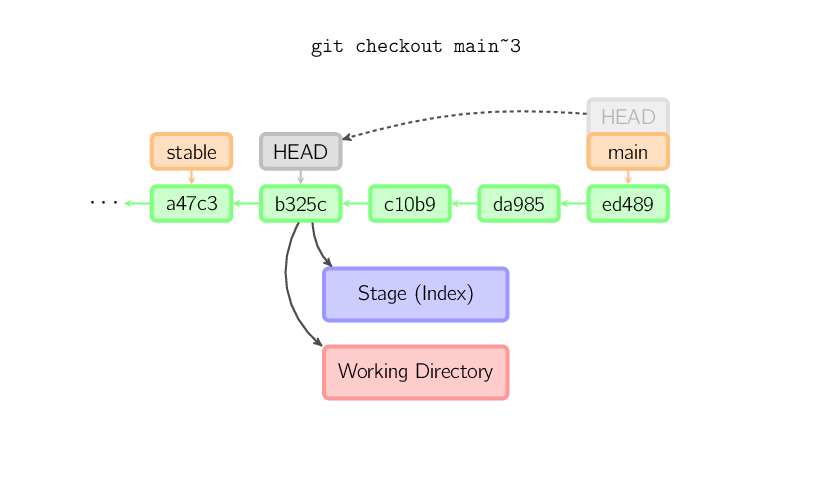
Kiedy HEAD zostanie odłączone, commity działają tak samo jak zazwyczaj, z tą różnicą, że żadna istniejąca i nazwana gałąź (branch) nie zostanie zaktualizowana. Można powiedzieć, że commit pojawi się w anonimowej gałęzi (branch).
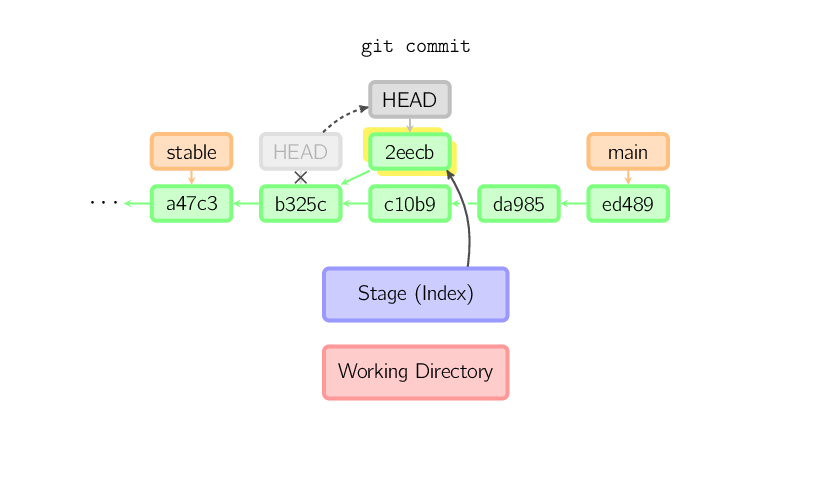
W momencie, w którym HEAD zostanie przeniesiony w dowolne inne miejsce, takie jak na przykład gałąź (branch) main, nic już nie wskazuje na dany commit, w związku z czym commit przepada. W poniższym przykładzie widać, że po wydaniu komendy nie ma żadnego dowiązania do commita 2eecb.
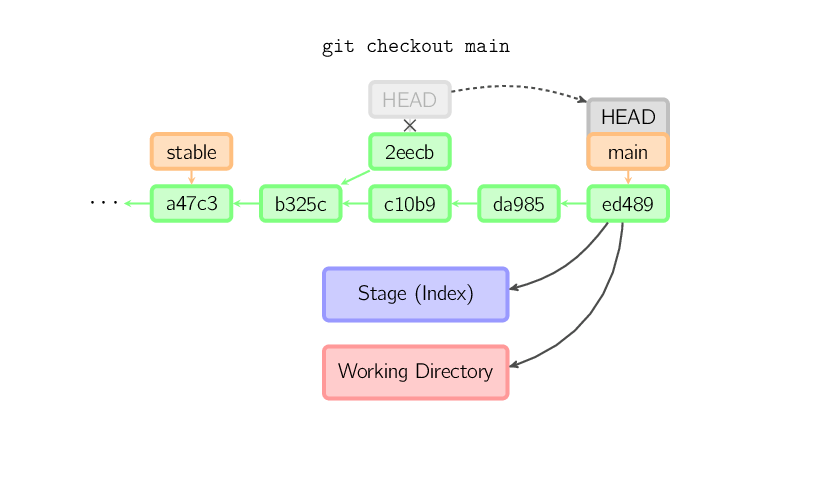
Jeśli istnieje potrzeba zapamiętania danego stanu, należy utworzyć nową lokalną gałąź (branch), wykorzystując do tego komendę git checkout -b nazwa.
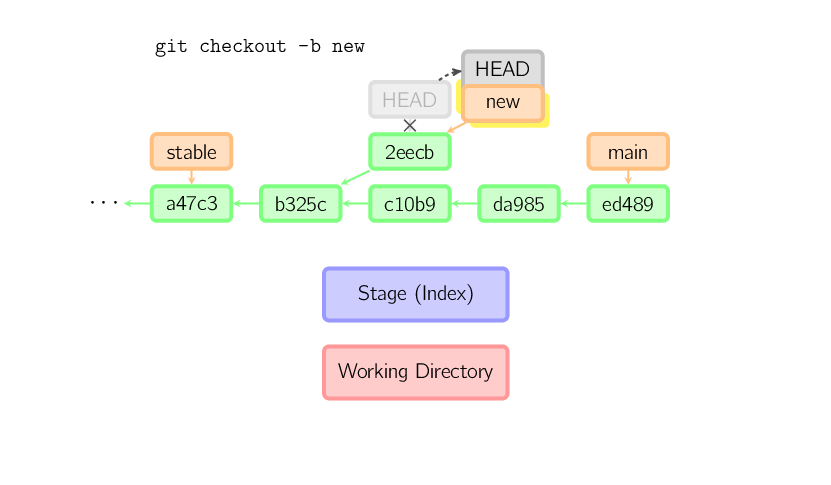
Komenda reset przenosi aktualną gałąź (branch) do wskazanej pozycji oraz opcjonalnie aktualizuje przechowalnię (stage) oraz katalog roboczy (working directory). Jest również używana do kopiowania plików z katalogu git (history) do przechowalni (stage) bez naruszania katalogu roboczego (working directory).
Jeśli zostanie podany commit, ale nie zostaną podane nazwy plików, aktualna gałąź (branch) zostanie przeniesiona do podanego commita, a przechowalnia (stage) zaktualizowana o jego zawartość. Jeśli zostanie dodany przełącznik --hard, zaktualizowany zostanie również katalog roboczy (working directory). Przełącznik --soft służy do przeniesienia gałęzi (branch) do wskazanego miejsca, jednak bez aktualizacji przechowalni (stage) oraz katalogu roboczego (working directory).
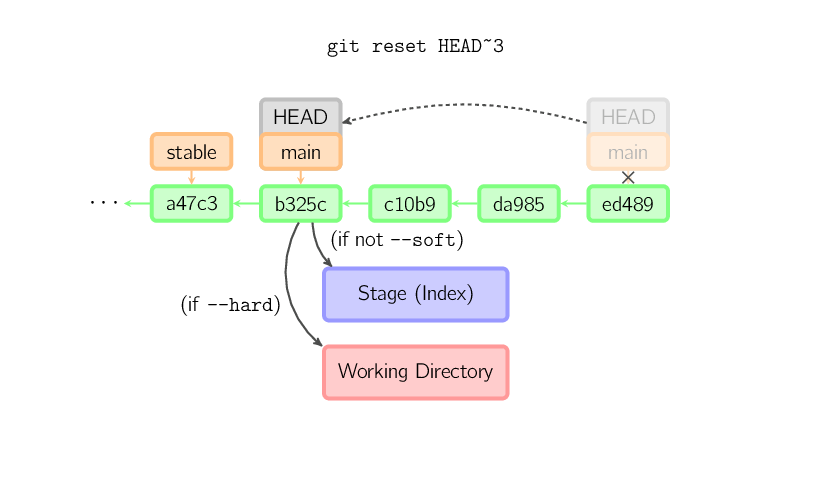
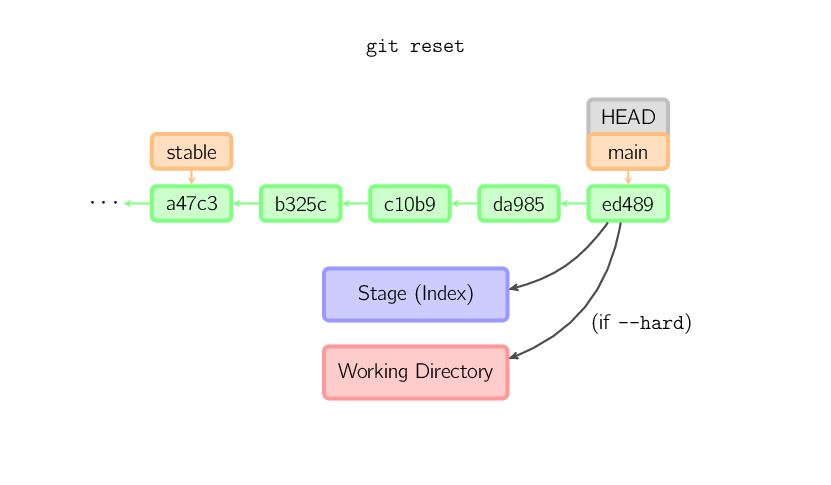
Jeśli commit nie zostanie podany, domyślnie gałąź (branch) wskazuje na HEAD. W takim przypadku nie nastąpi zmiana gałęzi (branch) - przechowalnia (stage) zostanie zresetowana do zawartości ostatniego commita (jeśli zostanie użyty przełącznik --hard resetowi ulegnie również katalog roboczy (working directory)).
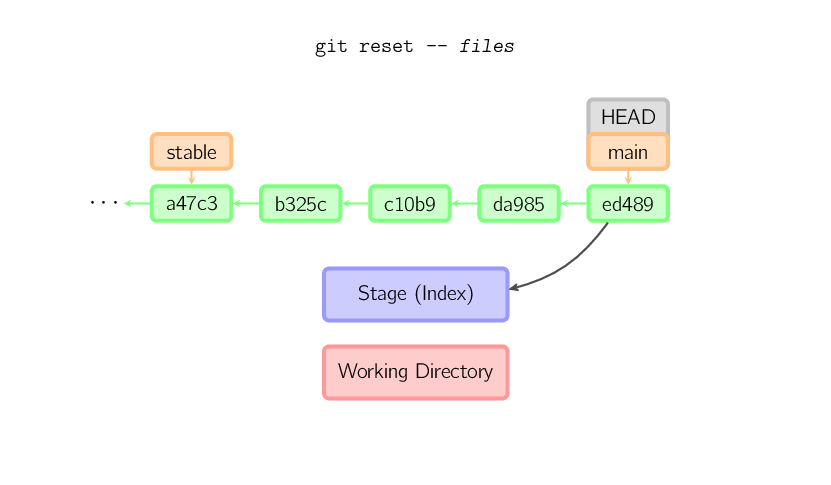
Jeśli zostanie podana nazwa pliku (lub wykorzystany zostanie przełącznik -p), komenda zadziała podobnie do checkout z podaną nazwą pliku, z tą różnicą, że zaktualizowana zostanie jedynie przechowalnia (stage), a nie katalog roboczy (working directory). Oczywiście zamiast używania HEAD można również sprecyzować commit, z którego zostaną skopiowane pliki
Scalanie (merge) tworzy nowy commit, który łączy w sobie zmiany zawarte w innych commitach. Przed wykonaniem scalania (merging), przechowalnia (stage) musi zawierać aktualny commit, do którego będzie następowało scalanie. Najprostszym przypadkiem jest taki, w którym inny commit jest przodkiem commitu, do którego chcemy scalać. Następnym prostym przypadkiem jest taki, w którym aktualny commit jest przodkiem innego commita, który chcemy scalić z aktualnym. Oba przypadki kończą się scalaniem (merge) poprzez fast-forward - wskaźnik zostaje przeniesiony w prosty sposób na nowy commit.
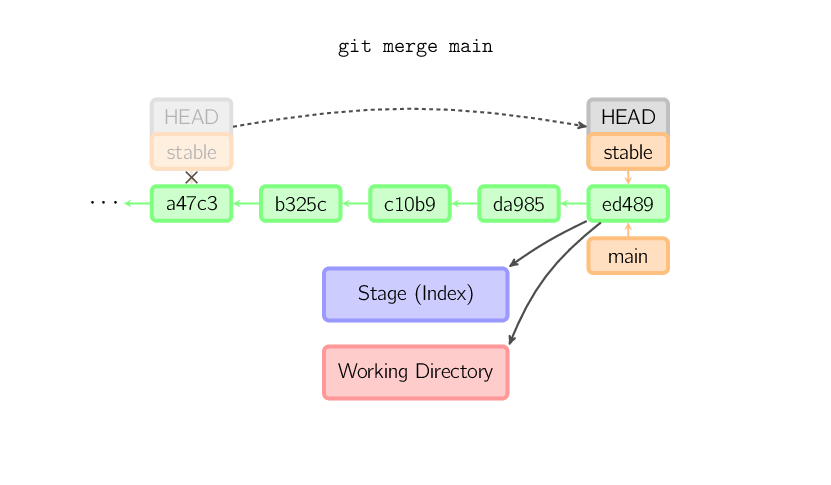
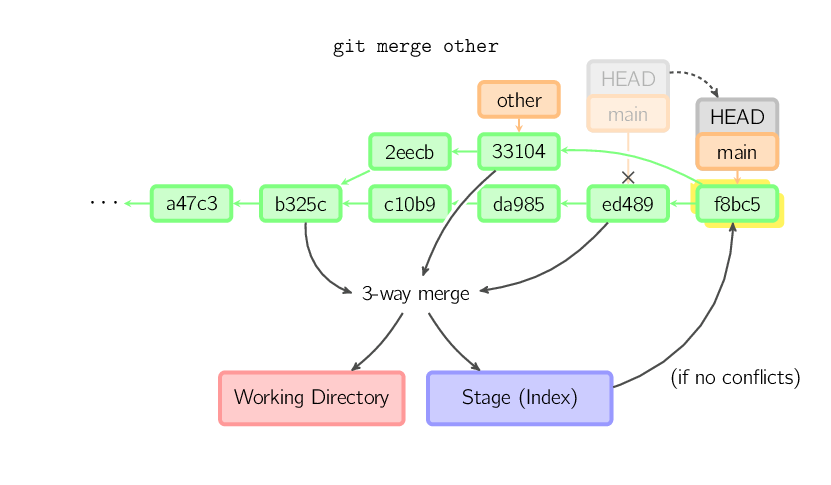
W każdym innym przypadku potrzebne jest "rzeczywiste" scalanie (merge). Można wybrać wiele strategii, ale domyślną jest wykorzystanie "rekursywnego" scalania (merge), która polega na wzięciu aktualnego commita, (ed489 poniżej), ostatniego commita gałęzi (branch), którą chcemy scalić z aktualną (33104) oraz wspólnego przodka obu tych commitów (b325c). Te trzy commity wykorzystywane są przez scalanie trójstronne (three-way merge). Rezultat scalania zapisywany jest zarówno do katalogu roboczego (working directory), jak i przechowalni (stage), a także pojawia się nowy commit, którego rodzicem jest 33104.
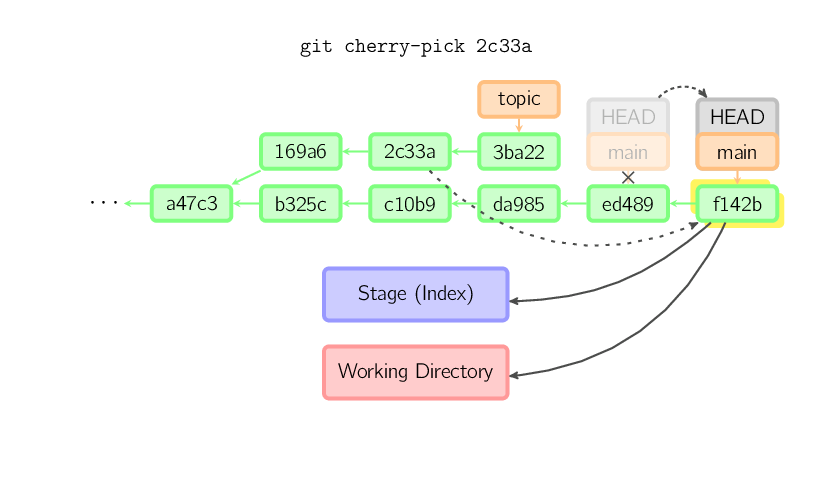
Komenda cherry-pick "kopiuje" wskazany commit i tworzy nowy commit w aktualnej gałęzi (branch), który zawiera identyczne zmiany jak wskazany commit.
Rebase jest alternatywą dla scalania (merge) w przypadku konieczności łączenia zmian z kilku gałęzi (branch). Scalanie (merge) nie zachowuje liniowej historii, tylko tworzy pojedynczy commit z dwoma rodzicami. Rebase natomiast powtarza commity z aktualnej gałęzi (branch) i odtwarza je w innej gałęzi, zachowując przy tym liniową historię. Tak naprawdę jest to sposób na wykonanie kilka razy komendy cherry-pick w sposób zautomatyzowany.
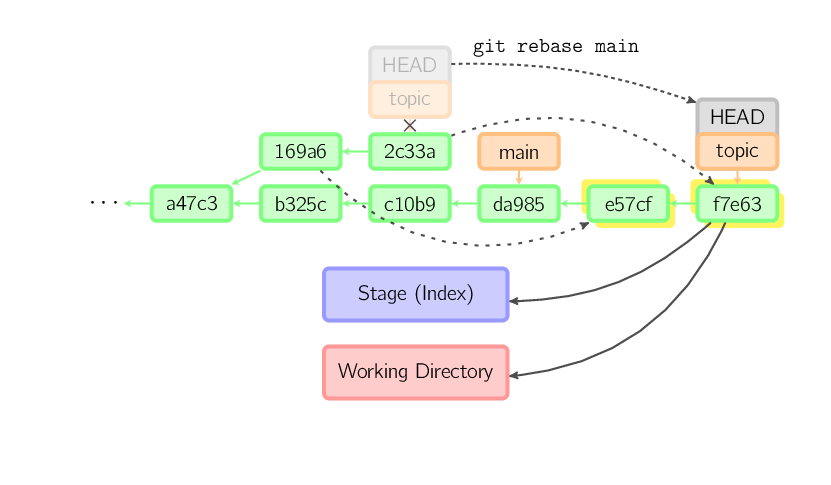
Powyższa komenda bierze wszystkie commity należące do gałęzi (branch) topic, ale które nie istnieją w main (widoczne jako 169a6 oraz 2c33a), następnie kopiuje je do gałęzi (branch) main i na końcu przenosi wskaźnik gałęzi (branch head) do nowego miejsca. Ważną informacją jest fakt, że wszystkie commity, które nie posiadają żadnego wskaźnika zostaną zutylizowane.
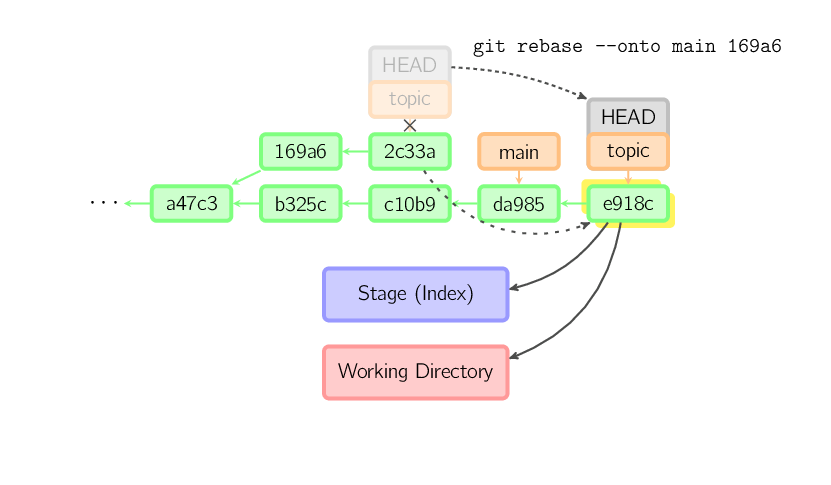
Aby ograniczyć historię commitów branych do rebase, należy użyć przełącznika --onto. Przedstawiona komenda przekopiuje do gałęzi (branch) main ostatnie commity z aktualnej gałęzi (branch) zaczynając od 169a6 (ale wykluczając ten commit), w tym przypadku będzie to commit oznaczony jako 2c33a.
Istnieje również komenda z przełącznikiem git rebase --interactive, która pozwala na wykonywania bardziej skomplikowanych operacji niż tylko samo powtarzanie commitów. Niestety nie istnieje żadna oczywista grafika, która w sposób jasny pomogłaby wyjaśnić jej działanie; więcej szczegółów można znaleźć pod tym linkiem: git-rebase(1)
Zawartość plików nie jest tak naprawdę trzymana w pliku index (.git/index) lub w obiektach będących commitami. Tak naprawdę każdy plik trzymany jest w bazie obiektów (object database) (.git/objects) jako obiekt zwany blob, który można zidentyfikować za pomocą hasha SHA-1. Plik index zawiera listę plików wraz z ich identyfikatorami przypisanymi do obiektów blob, a oprócz tego zawiera również inne dane. Na potrzeby commitów stworzony został inny typ danych, znany jako drzewa (tree), który również można zidentyfikować z wykorzystaniem hashy. Drzewa (trees) powiązane są z katalogami w katalogu roboczym (working directory) i zawierają listę drzew oraz obiektów typu blob, które połączone są z nazwami plików w danym katalogu. Każdy commit posiada identyfikator swojego "top-level tree", który z kolei zawiera wszystkie obiekty typu blob oraz inne drzewa (trees) powiązane z danym commitem.
Podczas wykonywania commita z odłączonym HEAD (detached HEAD), ostatni commit tak naprawdę posiada coś, co na niego wskazuje: reflog HEADa (historia wykonywanych zmian na headach). Mimo wszystko wskazanie to wygasa po krótkiej chwili, a w związku z tym commit może zostać zutylizowany, podobnie jak commity porzuconye przez komendy git commit --amend oraz git rebase.
Poniższe przykłady pokażą w jaki sposób następują zmiany w repozytorium podczas używania komend commit, checkout oraz reset. Podobnie działa polecany już Visualizing Git Concepts with D3, który symuluje je w sposób wizualny. Mam nadzieję, że poniższe przykłady okażą się pomocne.
Zacznijmy od stworzenia testowego repozytorium:
$ git init foo
$ cd foo
$ echo 1 > myfile
$ git add myfile
$ git commit -m "version 1"
Następnie zdefiniujmy funkcje, które pomogą nam w przeglądzie zmian:
show_status() {
echo "HEAD: $(git cat-file -p HEAD:myfile)"
echo "Stage: $(git cat-file -p :myfile)"
echo "Worktree: $(cat myfile)"
}
initial_setup() {
echo 3 > myfile
git add myfile
echo 4 > myfile
show_status
}
Na początku wszystkie elementy mają wersję 1.
$ show_status
HEAD: 1
Stage: 1
Worktree: 1
Poniżej możemy obserwować zmiany poszczególnych wersji podczas tworzenia commitu, począwszy od dodania plików do przechowalni (stage).
$ echo 2 > myfile
$ show_status
HEAD: 1
Stage: 1
Worktree: 2
$ git add myfile
$ show_status
HEAD: 1
Stage: 2
Worktree: 2
$ git commit -m "version 2"
[main 4156116] version 2
1 file changed, 1 insertion(+), 1 deletion(-)
$ show_status
HEAD: 2
Stage: 2
Worktree: 2
Sprawmy teraz, aby każdy z elementów repozytorium posiadał inną wersję.
$ initial_setup
HEAD: 2
Stage: 3
Worktree: 4
Spójrzmy, jak działa każda z komend. Zobaczysz, że działanie pokrywa się z diagramami umieszczonymi powyżej.
git reset -- myfile kopiuje z HEAD do przechowalni (stage):
$ initial_setup
HEAD: 2
Stage: 3
Worktree: 4
$ git reset -- myfile
Unstaged changes after reset:
M myfile
$ show_status
HEAD: 2
Stage: 2
Worktree: 4
git checkout -- myfile kopiuje z przechowalni (stage) do katalogu roboczego (worktree):
$ initial_setup
HEAD: 2
Stage: 3
Worktree: 4
$ git checkout -- myfile
$ show_status
HEAD: 2
Stage: 3
Worktree: 3
git checkout HEAD -- myfile kopiuje z HEAD zarówno do przechowalni (stage) jak i katalogu roboczego (worktree):
$ initial_setup
HEAD: 2
Stage: 3
Worktree: 4
$ git checkout HEAD -- myfile
$ show_status
HEAD: 2
Stage: 2
Worktree: 2
git commit myfile kopiuje z katalogu roboczego (worktree) do przechowalni (stage) oraz repozytorium (HEAD):
$ initial_setup
HEAD: 2
Stage: 3
Worktree: 4
$ git commit myfile -m "version 4"
[main 679ff51] version 4
1 file changed, 1 insertion(+), 1 deletion(-)
$ show_status
HEAD: 4
Stage: 4
Worktree: 4
Copyright © 2010, Mark Lodato. Polish translation © 2017, Emil Wypych
 Praca ta jest licencjonowana na warunkach Licencji Uznanie autorstwa-Użycie niekomercyjne-Na tych samych warunkach 3.0 Polska.
Praca ta jest licencjonowana na warunkach Licencji Uznanie autorstwa-Użycie niekomercyjne-Na tych samych warunkach 3.0 Polska.